
You've surely had this experience: you ask an AI to analyze a financial report, and it gives you a 700-word conclusion—the title says "neutral to expensive," but its own valuation table shows "upside of 10–30%." Self-contradictory. No auditing, no idea where the numbers come from.
This isn't because the AI isn't smart enough—it's because it lacks a method for getting things done.
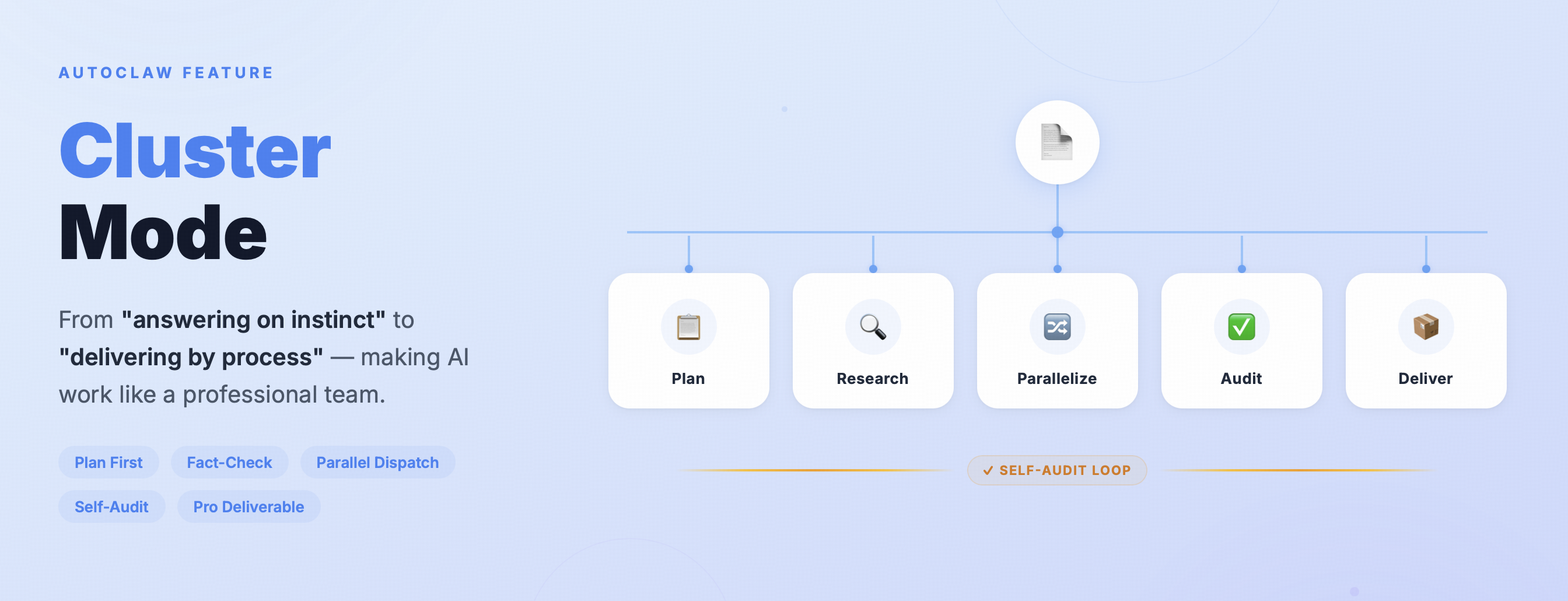
That's exactly where AutoClaw's Cluster Mode comes in: instead of relying on the model to "figure it out on its own," it enforces a strict SOP—understand the task, research, plan, dispatch parallel work, audit and verify, and deliver to spec—locking down every step: what to do and what standard to meet before moving forward.
Turning AI from "giving answers on instinct" to "delivering results by process."
What Do You Get When You Turn It On?
Normal mode is already an assistant that can search, use tools, and dispatch sub-agents. Cluster Mode adds five mandatory actions on top, elevating output from "usable" to "deliverable":
| Dimension | Normal Mode | Cluster Mode |
|---|---|---|
| How it works | Jumps in based on judgment | Creates a plan first, lists every step before acting |
| Where facts come from | May rely on the model's existing knowledge | Key facts are mandatorily verified online |
| Who does the work | Default: main thread; only pulls in help for very complex tasks | Defaults to parallel dispatch when dimensions can be split |
| Review mechanism | Submits as soon as done | Self-audits before submitting when conclusions/code/actionable advice are involved |
| Final deliverable | A block of text or Markdown | Roadshow-grade HTML, institutional-grade DOCX, investment-grade Deck Core philosophy: Simple tasks it handles solo; complex ones it assembles a team—like a small squad that adapts its formation to the mission. |
Four Things You'll Directly Feel
🎯 No More Black BoxA progress panel appears in the chat interface—which step it's on, which steps are done, what's remaining—all at a glance. Not a text promise of "I'll do it," but a real-time display of actual status.
🎓 Professional Answers for Professional DomainsWhen it hits domains that have been specifically optimized—finance, industry research—it knows what lens to apply, what entities to confirm first before expanding. Not the same generic template for every domain.
📦 Deliverables with Production QualitySimple answers that can be explained in a sentence or two are delivered as text; when visual output is needed, it goes into report format—web pages, documents, presentations—each with design constraints, proactively removing the "obviously AI-generated" cheap feel.
⚡ Parallel When Possible, Speed That Keeps UpWhen tasks can be split across dimensions, multiple roles work simultaneously—researching, writing, creating illustrations run in parallel, rather than one role doing everything serially. 18 researchers deployed simultaneously, producing a 20,000-word report in 43 minutes.
What Is It Good At?
Cluster Mode is specifically optimized for tasks that clearly require "doing it right":
- Financial Analysis — "Help me look at Company X's latest earnings report," "Pull a comparable valuation"
- Industry Research — "The AI coding tool competitive landscape," "Power battery recycling industry outlook"
- Deep Reading / Literature Review — "Explain this paper clearly," "Read these 5 articles and synthesize a summary"
- Long-Form Document Writing — "Write a white paper based on this outline," "Create an internal presentation"
- When not to use it: quick questions, single-step answers, casual chat—Cluster Mode launches an entire pipeline, and using a sledgehammer to crack a nut will actually be slower.
Real Cases
Below are real task benchmarks. Even within Cluster Mode, formation is automatically selected based on task complexity—broad research may involve 18 roles coordinating, while a single-company valuation needs only 2.
Case 1: A Week of New Developments in the Agent Space (Broad Research)
Input: "Keep an eye on what's new in the Agent space this past week, and synthesize a trend-worthy report"
- Deployed 18 researchers working in parallel: 1 scanner mapped the landscape first → 7 explored 7 directions simultaneously (product observations / academic scanning / framework ecosystems / China ecosystem / investment perspective / KOL scanning / dissenting views) → 7 deep-dived into each direction → lead writer drafted, independent reviewer audited, formatter produced HTML
- The reviewer caught 71 ghost citations + 5 duplicate reference numbers + 3 cross-dimension citation mismatches—that's why you can trust the numbers
- Delivered a ~20,000-word web report referencing 140+ web pages, with 6 cross-direction insights
- Completed in 43 minutes, with 21 intermediate notes available for review.
Case 2: Moutai Earnings + Valuation (Single-Company Analysis)
Input: "Kweichow Moutai's 2025 annual report is out—help me analyze the core financial metric changes and assess whether the current valuation is reasonable"
2 roles divided the work—single-company analysis doesn't need a crowd; the key is review quality:
- Lead Agent: Data collection → full-scope financial metric comparison → baijiu sector cross-valuation (vs Wuliangye, Yanghe, Fenjiu, Luzhou Laojiao) → comprehensive valuation assessment
- Reviewer independently audited and caught two layers of issues:At the number level: Series liquor decline "approx. -11%" was actually -9.76%, gross margin decline "approx. -1pct" was actually -0.75pct, and other decimal-level deviationsAt the logic level: Questioned the missing basis for deriving "reasonable PE 20-23×," and the overly definitive "margin of safety" phrasing, demanding revision before delivery
- → A sell-side Research Note-style web report with peer rankings + valuation conclusion + target price ¥1,725 (+34% upside)
- Completed in 8 minutes · Review-and-revise cycle · All data fully traceable.
Case 3: CRCL Q4 Research Report (Overseas Company Earnings Update)
Input: "Help me create an earnings update research report for Circle Internet Group (CRCL) Q4 2025"
2 roles collaborating—Lead Agent handles the main flow, pulling in a chart Worker for simultaneous chart generation:
- Lead Agent: Data collection → Beat/Miss analysis → Write 17-page DOCX research report → Review for number/logic/source cross-verification
- Chart generation: Simultaneously produced 10 PNG charts (quarterly revenue/EPS/gross margin/USDC circulation/Beat-Miss/valuation comparison, etc.)
- During self-review: Discovered the DOCX referenced chart_10_revenue_vs_usdc.png, but the actual filename was chart_10_rev_vs_usdc.png—self-identified the filename mismatch and fixed it, regenerating
- → A BUY rating / target price $135 / 17-page / DOCX research report with 10 embedded charts
- Completed in 13 minutes · Self-review and fix · Report + 10 charts fully traceable.
Case 4: MACD Quantitative Backtest (Programming + Audit)
Input: "I want to try a MACD golden cross / death cross strategy—write a version in Python, backtest it against the CSI 300 over the past 3 years, and output the return curve and key metrics"
3 roles divided the work:
- Lead Agent: Pulled 725 trading days of CSI 300 daily data via akshare as the standard dataset
- Quantitative Analyst: Wrote macd_backtest.py (EMA12/EMA26/DEA9 + golden cross/death cross trading engine), ran 32 trades + 16 metrics + return curve
- Reviewer: Independently rewrote the MACD formula in Python, verified each metric to 4 decimal places, sampled 6 trades for validation; 4-dimension audit all PASS, only WARN: discovered the first trade's −0.44% was an EMA initialization noise trade
- → A web report with 16 key metrics + return curve
- Honest conclusion: MACD strategy cumulative +12.51% vs buy-and-hold benchmark +27.82%, underperforming the market (31.25% win rate)—no sugarcoating, no beautification.
- Completed in ~10 minutes · Zero-deviation review · Code/data/charts fully traceable.
How to Use It?
AutoClaw main interface → right side of the chat input box → toggle on the "Agent Cluster Mode" button, then send your request.
Think of it as the entry point for when "I need to do this properly"—tasks that need deliverables, are somewhat complex, and deserve to be done right, turn it on; for casual chat, turn it off.
